
Summary: CALVIN is a neural network that can plan, explore and navigate in novel 3D environments. It learns tasks such as solving mazes, just by learning from expert demonstrations. Our work builds upon Value Iteration Networks (VIN) [1], a type of recurrent convolutional neural network that builds plans dynamically. While VINs work well in fully-known environments, CALVIN can work even in unknown environments, where the agent has to explore the environment in order to find a target.
The Problem
The problem we address is visual navigation from demonstrations. A robotic agent must learn how to navigate, given a fixed amount of expert trajectories of RGB-D images and the actions taken. While it is easy to plan with a top-down map that defines what are obstacles and targets, it is more challenging if the agent has to learn the nature of obstacles and targets from the RGB-D images.

Another important aspect of navigation is exploration. Our agent starts without any knowledge about the new environment, so it has to build a map of the environment as it navigates, and learn to explore areas that are most likely to lead to the target.

For the agent to be able to navigate in environments it hasn’t been trained on, it has to learn some general knowledge applicable across all environments. In particular, we focus on learning a shared transition model and reward model that best explain expert demonstrations, which can then be applied to new setups.

Model Overview
Our model consists of two parts — a learnt mapping component which we call Lattice PointNet, that aggregates past observations into a ground-projected map of embeddings, and CALVIN, which is a differentiable planner which models value iteration. Unlike more common approaches in reinforcement learning, where the agent sees an image and tries to reactively predict the best action, by having a proper spatial representation learnt by the Lattice PointNet and using CALVIN as a planning network, our agent is able to explore and navigate taking into account past observations in a spatially meaningful way.
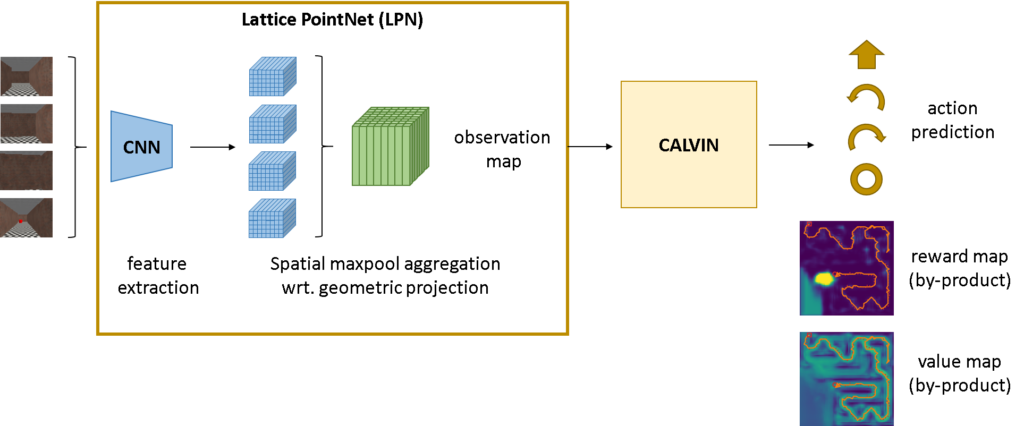
CALVIN is an improved version of Value Iteration Networks or VIN in short, which use recurrent convolution as a form of value iteration for spatial tasks. It learns a reward map and a convolutional kernel that, applied following the value iteration update equation, produces a Q-value map, which is an estimate of the future rewards the agent can obtain. Once the value map is computed, the agent can take the action that yields the highest value to maximise its chances.
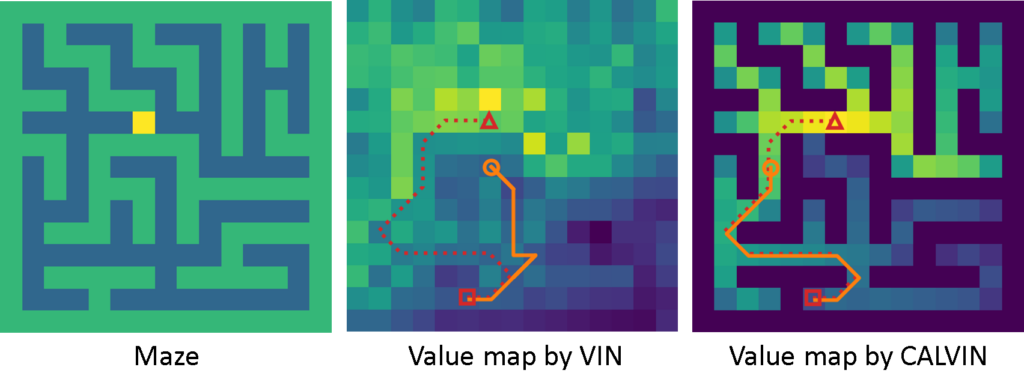
While the VIN is a simple architecture, it has several drawbacks, most notably that it doesn’t strictly learn value iteration in practice. To illustrate this, let us consider the maze shown in the figure below. We would expect that the cells will have higher values according to the path length from the target cell, and that all invalid cells (e.g. walls of the maze) should have non-positive values because the agent should not be incentivised to visit them. In fact, our model CALVIN learns to produce a value map (shown on the right) that is almost identical to the theoretical solution. On the other hand, the value map produced by the VIN is non-interpretable and does not correctly represent the information about obstacle cells. We identified the mismatch to be because the VIN is not constrained enough to penalise obstacles, hence making suboptimal decisions such as repeatedly exploring dead-ends.
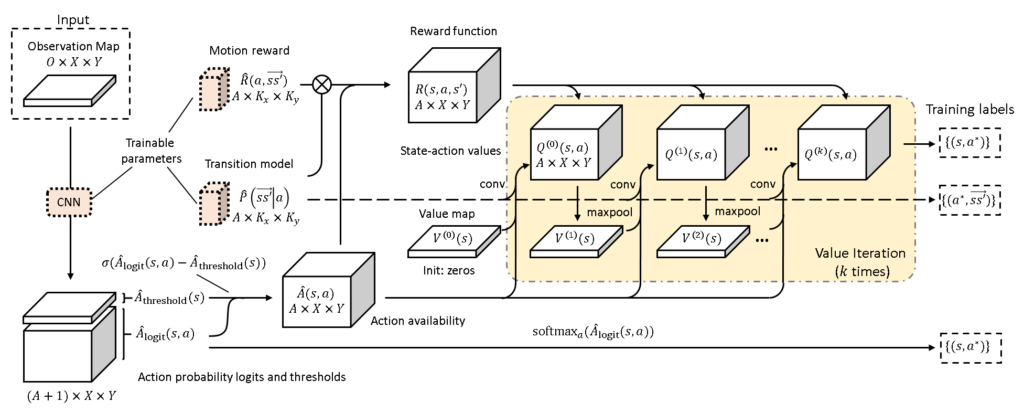
CALVIN, on the other hand, explicitly learns valid and invalid transitions. It decomposes the transition model into a shared agent motion model and an action availability model. CALVIN uses the action availability model to penalise the invalid actions, and to prevent values from propagating from unreachable states. In addition to these constraints on available actions, we also improved the training loss so that the model can leverage training signals across the entire trajectory, instead of just the current state.
Experiments
We performed experiments, specifically on exploration of novel unknown environments, in three domains: a grid maze environment, MiniWorld [2], and the Active Vision Dataset [3]. CALVIN achieved a more robust navigation, even in unknown environments, demonstrating explorative behaviour which the VIN lacks.
In our grid maze setup, the agent can only view the maze locally. The agent can choose to either move forward, rotate left, right, or trigger done. We can see that the agent predicts higher values for places the agent hasn’t explored yet, and a high reward for the target location when the agent sees it.
Next, we ran a similar experiment in a 3D maze environment called MiniWorld, but this time using RGB-D image sequences from the agent’s perspective rather than a top-down view. While the agent navigates, it builds up a map of embeddings with the Lattice PointNet, which is then fed into CALVIN. Here too, the agent has learned to assign lower values to walls and higher values to unexplored locations. We can observe that the agent manages to backtrack upon hitting a dead-end, and replan towards other unexplored cells. When the agent sees the target, it assigns a high reward to cells near the target.
Finally, we tested the agent using the Active Vision Dataset, which is a collection of real-world images obtained by a robotic platform, from which we can create trajectories. For this task, we used pre-trained ResNet embeddings and fed them into the Lattice PointNet. The agent was trained to navigate towards a soda bottle in the room.
Conclusion
CALVIN is able to explore and navigate unknown environments more robustly compared to other differentiable planners. This improvement from the VIN comes from explicitly modelling action availability, used to penalise invalid actions, together with an improved training loss that uses trajectory reweighting. We also introduced a Lattice PointNet backbone that efficiently fuses past observations in a spatially consistent way.
For further details, please check out our paper and our open-sourced code.